
機械学習で株価を予測することに挑戦していきます。前回に引き続き、scikit-learnで過去の株価データと為替データを基に学習し、株価予測を行います。今回はワンホットエンコーディング(ダミー変数)とビニング、交互作用特徴量や多項式特徴量で特徴量表現を豊かにし、精度を改善できるかを確認していきます。
関連記事
機械学習で株価予測~scikit-learnで株価予測②:特徴量選択とデータの標準化、正規化~
機械学習で株価予測~scikit-learnで株価予測④:世界の主要指数の追加~
環境
- OS:Windows10
- Python:3.6.5
- sklearn:0.19.1
概要
目標
様々なデータ(経済指標、為替レート、ダウ平均等)に基づいて、翌日の株価日足が陽線/陰線のどちらかになるのかを予測(分類)するモデルを作成することを目標とします。
予測対象銘柄
日経225連動型上場投資信託
使用する機械学習ライブラリと学習手法
- 使用ライブラリ:scikit-learn
- アルゴリズム:線形SVM(線形サポートベクターマシーン)
- 学習手法:教師あり学習
使用データ
株価データ
株式投資メモ・株価データベース(https://kabuoji3.com)様に掲載されている過去の株価データを使用させていただいています。
為替データ
みずほ銀行様のヒストリカルデータを使用させていただいています。
今回のベースモデル
データ作成部分のソースコード
前回からの変更点
入力データについて
これまでは株価データのみを入力としていましたが、今回から各国の為替データを加えています。
目的変数の付与方法を変更
前回までは前日の終値と当日の終値を比較し、上昇率が正の値であったものを1、負の値であったものを0として目的変数を作成していましたが、目的は株価日足が陽線/陰線のどちらかになるのかを予測することですので、比較するべきは同一日の始値と終値であるということに今更気が付きました。その為、今回から始値 ≦ 終値であれば1、そうでなければ0としています。
グリッドサーチで探索するパラメーターの値を変更
グリッドサーチで正則化項(C)を探索する際の範囲を広くしています。
為替レートを入れた結果
目的変数の作成方法を変更したことにより最終的に精度は50%程度となりましたが、前回までと同様の方法(終値と当日の終値を比較)で目的変数を作成したモデルへ為替レートのデータを加えると精度が60%以上へと改善された為、為替レートの中には有用な説明変数が存在すると思われます。しかし、特徴量選択を行っても精度が改善されないことから、このままの状態で特徴量を絞ることに意味はなさそうです。そこで、今回は特徴量の重要度を可視化し、それを基に特徴量の表現を拡張することにより精度が改善されるかどうか確認します。
特徴量の重要度を可視化する
ランダムフォレストのような決定木ベースのアンサンブル分析器では特徴量の重要度を算出することが出来ます。そこで、ランダムフォレストで特徴量の重要度を評価してみます。
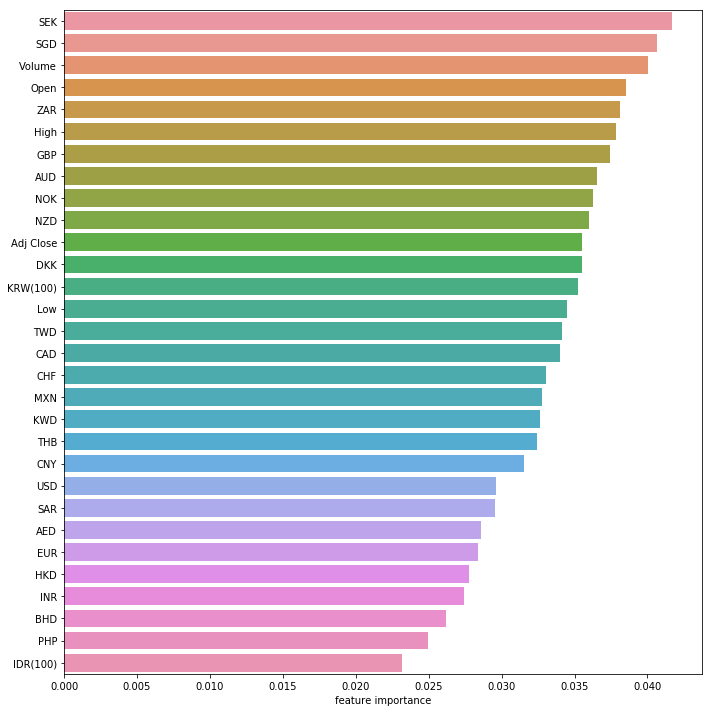
SEK(スウェーデン・クローナ)やSGD(シンガポールドル)、出来高などの変数が重要であるという結果が出てきました。意外なことにUSD(アメリカ合衆国ドル )やEUR(ユーロ)は下位のほうにランク付けされています。相関係数も併せて確認したところ、幾つか相関の強い変数があった為、重要度の低い不要な通貨を削除します。
しかし、不要な通貨を削除して再度学習させましたが、結果は変わりませんでした。現状のままではこれ以上の精度の向上が難しそうなので、データの表現方法を拡張してみます。
# 正解率の計算
train_score = accuracy_score(y_train, y_train_pred)
test_score = accuracy_score(y_test, y_val_pred)
# 正解率を表示
print("トレーニングデータに対する正解率:" + str(train_score * 100) + "%")
print("テストデータに対する正解率:" + str(test_score * 100) + "%")
トレーニングデータに対する正解率:51.667186039264564%
テストデータに対する正解率:51.18306351183064%
ワンホットエンコーディング(ダミー変数)
ワンホットエンコーディングとは、カテゴリー変数を表現する際によく用いられる手法です。ダミー変数とも呼ばれます。n種からなるカテゴリー変数をn個の0と1の値を持つ新しい特徴量に置き換えることにより、線形2クラスの分類式で扱いやすくすることが出来ます。今回は 月(1~12)、日(1~31)、曜日(月曜が0, 日曜が6)をそれぞれ新たな特徴量へ置き換えます。
例えば「月(1~12)」の場合、情報を抽出した段階では「month」という列の中に1~12の数を持っている状態です。
| month |
| 5 |
これを、「 pd.get_dummies」で変換すると、以下のように0と1の値を持つ特徴量が新たに生成されます。
| month1 | month2 | month3 | month4 | month5 | month6 | month7 | month8 | month10 | month11 | month12 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
#ワンホットエンコーディング
## 月(1~12)、日(1~31)、曜日(月曜が0, 日曜が6)情報の抽出
dummyData = pd.DataFrame({
'month' : merge_Data['日付'].dt.month,
'day' : merge_Data['日付'].dt.day,
'weekday' : merge_Data['日付'].dt.dayofweek
})
## 月、曜日情報をダミー変数へ変換
dummyData = pd.get_dummies(dummyData, columns=['month','day','weekday'])
## 最初の5行を表示
dummyData.head()
ビニング
ビニングとは、特徴量をビンと呼ばれる離散値カテゴリーに分散する手法です。今回は重要度が高い上位5つの特徴量を10分割し、カテゴリー変数化してみます。
# ビニング ## SEK 10分割 merge_Data_change['SEK_bin'] = pd.qcut(merge_Data_change['SEK'], q=10) ## SGD 10分割 merge_Data_change['SGD_bin'] = pd.qcut(merge_Data_change['SGD'], q=10) ## Volume 10分割 merge_Data_change['Volume_bin'] = pd.qcut(merge_Data_change['Volume'], q=10) ## Open 10分割 merge_Data_change['Open_bin'] = pd.qcut(merge_Data_change['Open'], q=10) ## ZAR 10分割 merge_Data_change['ZAR_bin'] = pd.qcut(merge_Data_change['ZAR'], q=10) # ダミー変数へ変換 merge_Data_change = pd.get_dummies(merge_Data_change, columns=['SEK_bin','SGD_bin','Volume_bin','Open_bin','ZAR_bin'])
ここまでやった段階で再学習させてみると、ほんの僅かですが精度が向上しており、今回加えた説明変数の中に有用なものがあることがわかります。
# 正解率の計算
train_score = accuracy_score(y_train, y_train_pred)
test_score = accuracy_score(y_test, y_val_pred)
# 正解率を表示
print("トレーニングデータに対する正解率:" + str(train_score * 100) + "%")
print("テストデータに対する正解率:" + str(test_score * 100) + "%")
トレーニングデータに対する正解率:53.069492053599255%
テストデータに対する正解率:51.43212951432129%
再度特徴量の重要度を評価し、結果を確認します。
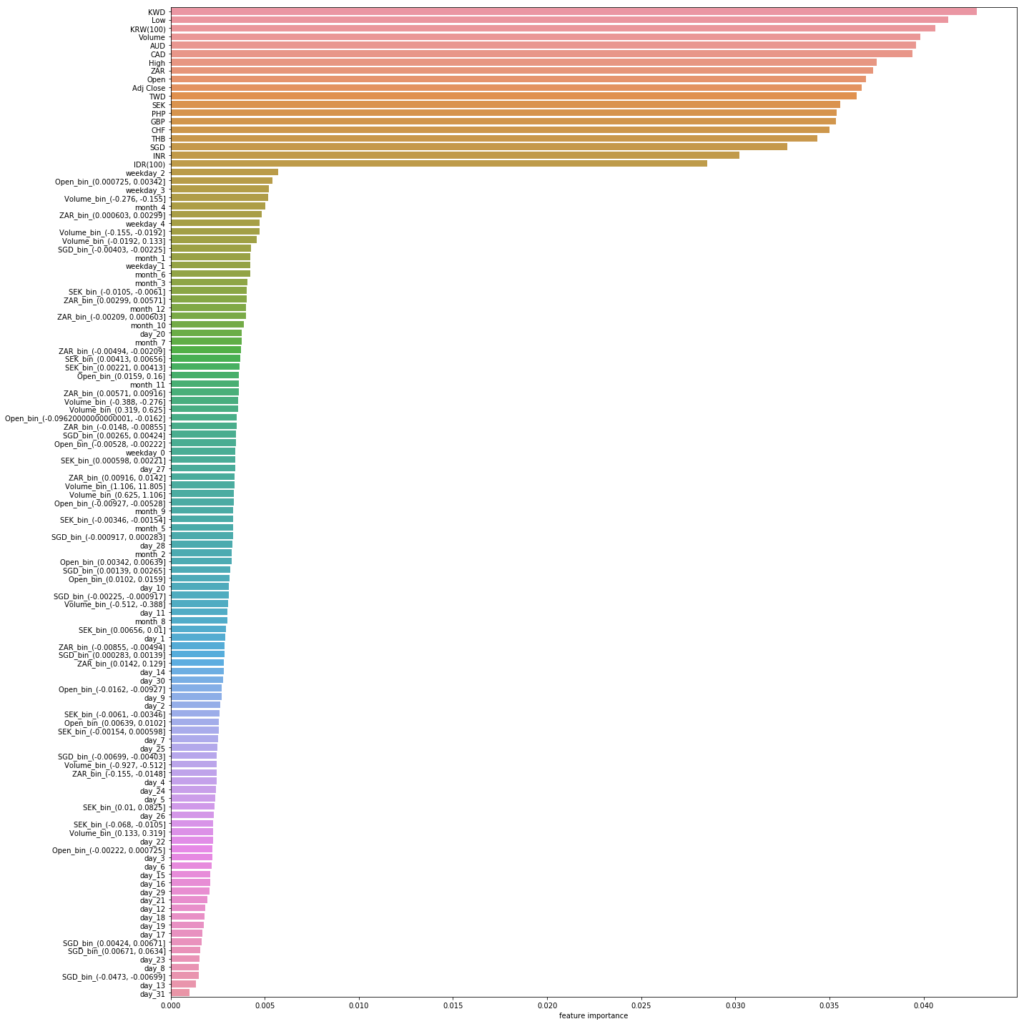
結果としては、今回加えた特徴量はいずれも既存の特徴量よりも重要度は下回っているようです。どの説明変数が精度に寄与しているのかが直感的に分からないため、日付のカテゴリー変数化、ビニングそれぞれどちらかのみを実施した際の精度を確認してみます。
- 日付のカテゴリー変数のみの場合
# 正解率の計算
train_score = accuracy_score(y_train, y_train_pred)
test_score = accuracy_score(y_test, y_val_pred)
# 正解率を表示
print("トレーニングデータに対する正解率:" + str(train_score * 100) + "%")
print("テストデータに対する正解率:" + str(test_score * 100) + "%")
トレーニングデータに対する正解率:56.466188843876594%
テストデータに対する正解率:47.19800747198008%
- ビニングのみの場合
# 正解率の計算
train_score = accuracy_score(y_train, y_train_pred)
test_score = accuracy_score(y_test, y_val_pred)
# 正解率を表示
print("トレーニングデータに対する正解率:" + str(train_score * 100) + "%")
print("テストデータに対する正解率:" + str(test_score * 100) + "%")
トレーニングデータに対する正解率:51.91648488625739%
テストデータに対する正解率:51.18306351183064%
どちらかのみにすると精度が低下する為、追加した説明変数は何らかの要因で精度向上に寄与していると考えられます。その為、今回はどちらもこのまま残します。
交互作用特徴量と多項式特徴量
特徴量表現を拡張するもう1つの手段として、交互作用特徴量と多項式特徴量の生成という手段があります。交互作用特徴量とは特徴量の交互作用を表すための特徴量で、特徴量同士の積で表します。例えば、x1、x2という特徴量がある場合、x1 * x2という特徴量を新たに作成します。
また、多項式特徴量とは特徴量の多項式表現を新たな特徴量とする方法です。例えば、x1、x2の特徴量の2次の表現を作ると、x1^2、x2^2という特徴量が新たに作成されます。
まず、データの正規化の後に以下のコードを挿入し、全ての説明変数を対象に交互作用特徴量と2次までの多項式特徴量を作成しています。
# 多項式特徴量を追加 poly = PolynomialFeatures(degree=2, include_bias=False) poly.fit(explanatory_variable) explanatory_variable_poly = poly.transform(explanatory_variable)
交互作用特徴量と多項式特徴量を加えたことにより、精度が以下のように変化しました。全ての説明変数の表現を拡張したことによりトレーニングデータに完全にフィッティングしたようですが、テストデータに対する精度が示す通り、未知のデータの対する精度は向上していません。
# 正解率の計算
train_score = accuracy_score(y_train, y_train_pred)
test_score = accuracy_score(y_test, y_val_pred)
# 正解率を表示
print("トレーニングデータに対する正解率:" + str(train_score * 100) + "%")
print("テストデータに対する正解率:" + str(test_score * 100) + "%")
トレーニングデータに対する正解率:100.0%
テストデータに対する正解率:51.55666251556662%
そこで、ビニングと同様に重要度が高い上位5つの特徴量のみを対象として交互作用特徴量と多項式特徴量を作成して再度学習をしてみました。トレーニングデータへのオーバーフィッティングが無くなった一方、テストデータへの精度に変化はありません。
# 正解率の計算
train_score = accuracy_score(y_train, y_train_pred)
test_score = accuracy_score(y_test, y_val_pred)
# 正解率を表示
print("トレーニングデータに対する正解率:" + str(train_score * 100) + "%")
print("テストデータに対する正解率:" + str(test_score * 100) + "%")
トレーニングデータに対する正解率:53.007167341851044%
テストデータに対する正解率:51.55666251556662%
再度特徴量の重要度を評価し、結果を確認します。追加した交互作用特徴量と多項式特徴量が上位にランク付けされており、精度の向上に寄与していることがわかります。
![]()
そこで、現状のモデルの汎化性能を評価してみます。
交差検証
交差検証とはデータ分割を何度も繰り返して行い、複数のモデルを訓練する手法です。例えばデータを5分割した場合、1回目はそのうちの一つをテストデータ、それ以外を学習データとして、学習・評価します。2回目は1回目と異なる別のデータをテストデータとして使い、3回目は1,2回目と異なるデータで評価をします。そして、各回で測定した精度の平均を取ります。こうしてデータを交差して評価するという事を繰り返し、平均化することによりたまたまテストデータに特定のデータが偏っているという事象を防ぐことが出来、モデルの汎化性能を適切に評価することが出来ます。

今回は5分割して交差検証を行っています。結果、各スコア平均値は53.8%程度となり、このモデルの現状の精度は約51%程度であり、汎化性能はあまり向上しないことがわかります。
# 交差検証
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable, answers, cv = 5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
Cross-Validation scores: [0.51681196 0.51307597 0.50560399 0.50498753 0.51560549]
Average score: 0.5112169859321145
他のアルゴリズムによる評価
ここまで線形サポートベクターマシーンで評価を行ってきましたが、同じ線形モデルの代表例であるロジスティック回帰と、アンサンブル学習の手法の一つであるランダムフォレストで結果がどうなるか確認してみます。
ロジスティック回帰
ロジスティック回帰は線形サポートベクターマシーンと同様のデータを用いて学習を行っています。線形サポートベクターマシーンと同じような傾向の結果が出ていることが確認できます。
# 正解率の計算
train_score = accuracy_score(y_train, y_train_pred)
test_score = accuracy_score(y_test, y_val_pred)
# 正解率を表示
print("トレーニングデータに対する正解率:" + str(train_score * 100) + "%")
print("テストデータに対する正解率:" + str(test_score * 100) + "%")
トレーニングデータに対する正解率:56.902461826114056%
テストデータに対する正解率:48.06973848069738%
# 交差検証
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable, answers, cv = 5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
Cross-Validation scores: [0.52054795 0.50809465 0.5143213 0.48503741 0.48314607]
Average score: 0.5022294718658319
ランダムフォレスト
ランダムフォレストはグリッドサーチの結果、決定木の数が100の場合が最も良いと判断され、その影響でトレーニングデータにフィッティングしてしまいました。交差検証の結果は線形サポートベクターマシーンやロジスティック回帰と同レベルであることがわかります。
# 正解率の計算
train_score = clf.score(X_train , y_train)
test_score = clf.score(X_test, y_test)
# 正解率を表示
print("トレーニングデータに対する正解率:" + str(train_score * 100) + "%")
print("テストデータに対する正解率:" + str(test_score * 100) + "%")
トレーニングデータに対する正解率:97.97444686818324%
テストデータに対する正解率:49.19053549190536%
# 交差検証
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable, answers, cv = 5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
Cross-Validation scores: [0.5143213 0.50809465 0.49937733 0.49376559 0.52059925]
Average score: 0.507231622437835
まとめ
ワンホットエンコーディング(ダミー変数)とビニング、交互作用特徴量、多項式特徴量と試し、精度向上に一定の効果があることを確認することが出来ました。とはいえ、まだ51%の精度しか得られておらず、まだまだ意味のあるモデルとは言えません。モデルのパラメーターをチューニングすることでもう少し適切に精度を向上できる可能性もありますが、精度を大きく向上させるには有用な説明変数を増やすことが必要となる場合が多いそうです。そこで次回は各国の指標データを加えて精度が改善されるか確認を行いたいと思います。
記事執筆終了地点のソースコード
参考書籍
オライリーから出版されているの「Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎」の内容を参考にしています。機械学習に必要な基礎知識が網羅的に記載されており、これから機械学習を始めようと思っている方にはとてもおすすめです。