
機械学習で株価を予測することに挑戦していきます。今回は世界の主要指数を説明変数に加え、精度を改善できるかを確認します。
関連記事
機械学習で株価予測~scikit-learnで株価予測②:特徴量選択とデータの標準化、正規化~
機械学習で株価予測~scikit-learnで株価予測③:特徴量の重要度を可視化し、ワンホットエンコーディング、ビニング、交互作用特徴量、多項式特徴量を試す~
環境
- OS:Windows10
- Python:3.6.5
- sklearn:0.19.1
概要
目標
様々なデータ(経済指標、為替レート、ダウ平均等)に基づいて、翌日の株価日足が陽線/陰線のどちらかになるのかを予測(分類)するモデルを作成することを目標とします。
予測対象銘柄
日経225連動型上場投資信託
使用する機械学習ライブラリと学習手法
- 使用ライブラリ:scikit-learn
- アルゴリズム:線形SVM(線形サポートベクターマシーン)、ロジスティック回帰、ランダムフォレスト、XGboost、LightGBM
- 学習手法:教師あり学習
使用データ
株価データ
株式投資メモ・株価データベース(https://kabuoji3.com)様に掲載されている過去の株価データを使用させていただいています。
為替データ
みずほ銀行様のヒストリカルデータを使用させていただいています。
世界の主要指数のデータ
米国のYahoo! Finance様から過去のcsvデータをダウンロードし、使用させていただいています。
今回のベースモデル
データ作成部分のソースコード
データ作成について
今回追加した世界の主要指数
以下の指数を追加しています。今回はYahoo! Financeから取得可能な指数は基本的にはすべて入れ、そこから説明変数を絞りこむ方針です。
- SSE Composite Index
- ALL ORDINARIES
- S&P/ASX 200
- BEL 20
- S&P BSE SENSEX
- IBOVESPA
- Dow 30
- CAC 40
- DAX PERFORMANCE-INDEX
- S&P 500
- S&P/TSX Composite index
- HANG SENG INDEX
- IPSA SANTIAGO DE CHILE
- Nasdaq
- Jakarta Composite Index
- KOSPI Composite Index
- MERVAL
- IPC MEXICO
- EURONEXT 100
- NYSE COMPOSITE (DJ)
- Russell 2000
- TSEC weighted index
- Vix
- NYSE AMEX COMPOSITE INDEX
欠損値の補完
指数データの中身を確認すると、幾つかの指数で欠損値が存在したため補完をしています。時系列データであることから、今回は前の値で補完を行いました。
前回使用したカテゴリー変数や交互作用特徴量、多項式特徴量について
前回日付情報のカテゴリー変数化や重要な特徴量の交互作用特徴量、多項式特徴量の作成を行いましたが、単純に指数データを説明変数に加えたことによる影響を見たかったので一旦外してベースモデルを作成しています。
世界の主要指数を加えた結果
前回株価データと為替データのみで作成したモデルは約51%の精度であったのに対し、指数データを加えたことにより交差検証時の精度が約52%となりました。僅かなではありますが精度の向上に寄与していると思われるので、株価データ・為替データ・指数データを説明変数として更なる精度の向上に挑戦します。
特徴量の重要度の可視化して検討する
まずは前回と同様に特徴量の重要度を可視化し、その結果を基に精度が向上できないか検討します。前回はランダムフォレストのみを使用していましたが、今回から新たにXGBoostとLightGBMも加え、それぞれ特徴量の重要度を出力させています。
また、パラメータのチューニングは行っていない状態で重要度の判定は行っています。アルゴリズムによって重要度の上下関係が異なる場合、最も精度の良いXGBoostの結果を重視して判断をしています。
- ランダムフォレスト
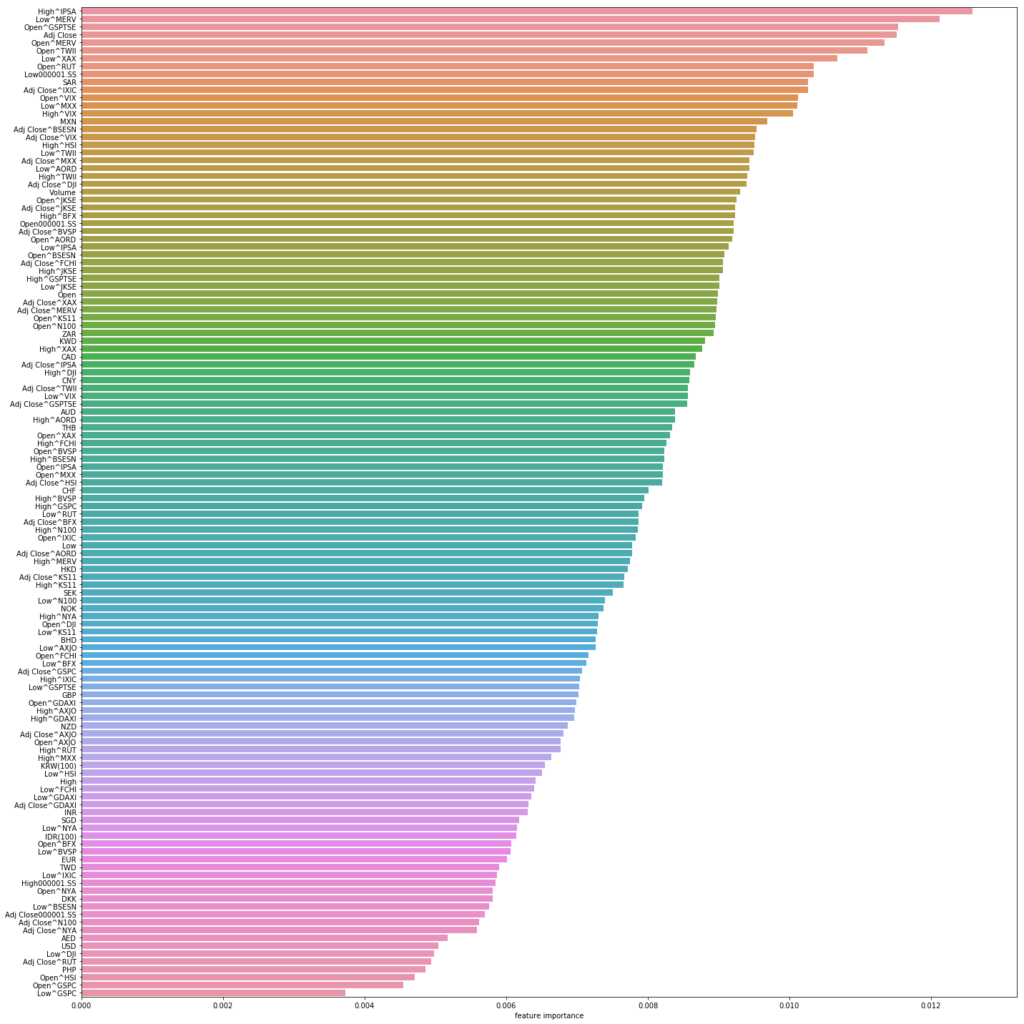
# 交差検証
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable, answers, cv=5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
Cross-Validation scores: [0.51925466 0.50310559 0.50310559 0.52179328 0.52552927]
Average score: 0.5145576757965084
- LightGBM
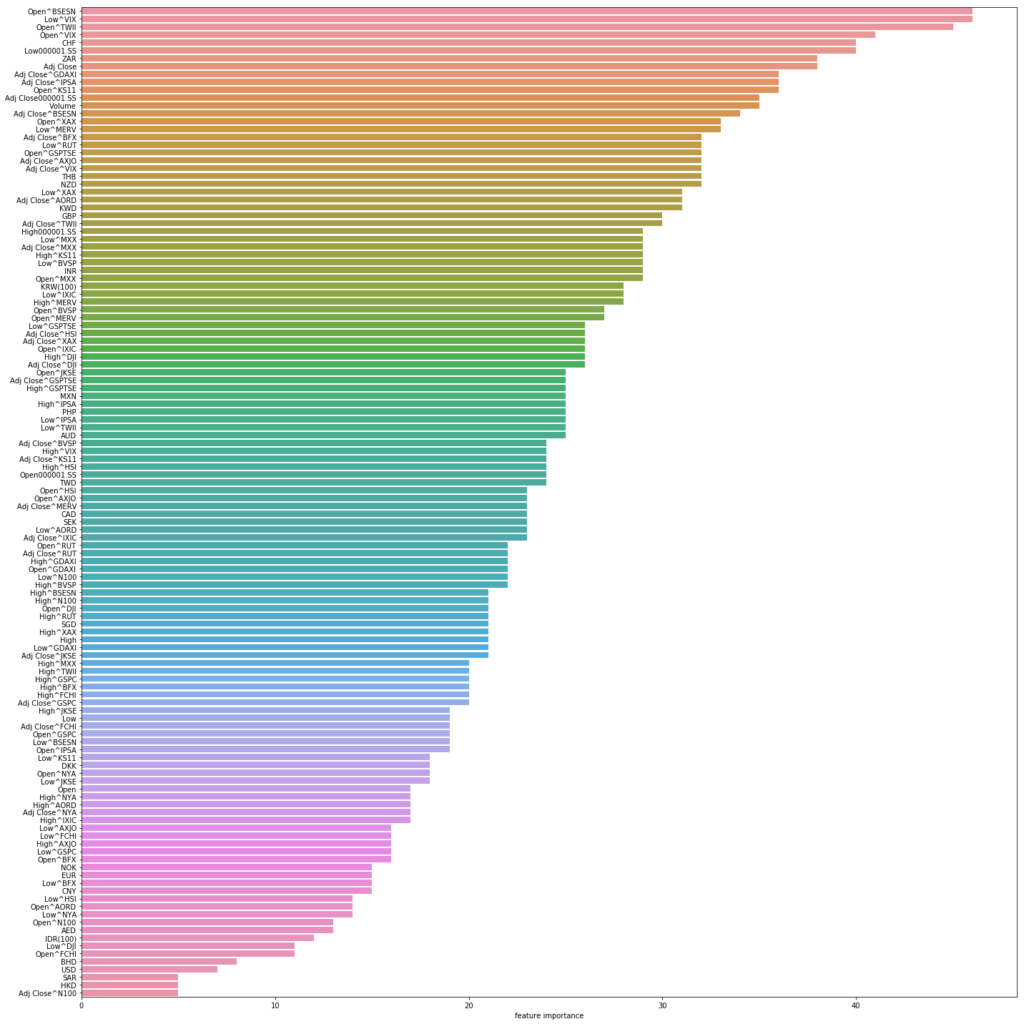
# 交差検証
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable, answers, cv=5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
Cross-Validation scores: [0.50559006 0.53167702 0.48571429 0.52552927 0.52926526]
Average score: 0.5155551774015145
- XGboost

# 交差検証
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable, answers, cv=5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
Cross-Validation scores: [0.51925466 0.52298137 0.51677019 0.49439601 0.5267746 ]
Average score: 0.5160353642783659
相関の強い説明変数の削除
重要度と同時に相関係数に関しても可視化していた為、まず相関の強い説明変数同士で重要度の低い以下の説明変数を削除を行いました。
- USD
- EUR
- DK
- NOK
- NZD
- BHD
- CNY
- HKD
- SAR
- AED
- MXN
しかし削除後に精度を測りなおしたところ、精度が低下しています。
# 交差検証
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable, answers, cv=5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
Cross-Validation scores: [0.50931677 0.51801242 0.51801242 0.52926526 0.53673724]
Average score: 0.5222688211133715
今回追加した指数同士でも相関がかなり強い変数がありますが、そちらについても単純に削除しても精度が落ちるのみでした。その為、今回は相関が強い場合でも説明変数を取り除くことをしない方針としました。
交互作用特徴量と多項式特徴量の追加
重要と思われる特徴量の交互作用特徴量と多項式特徴量の生成をし、表現を拡張することで精度が向上するか確認します。アルゴリズムによりランキングが異なる為、見比べながら諸々試しましたが、XGBoostで重要と評価された以下の上位5つの説明変数に対し、2次までの交互作用特徴量、多項式特徴量を生成しました。
- Low^VIX
- Open^TWII
- Adj Close^GSPC
- Adj Close^KS11
- Adj Close^AORD
# 交差検証
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable, answers, cv=5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
Cross-Validation scores: [0.55776398 0.57515528 0.56149068 0.54669988 0.58655044]
Average score: 0.5655320498441404
LightGBMとXGBoostで共通で選ばれている説明変数を対象としたり、各アルゴリズムの上位5つを対象にしてみる等、幾つか試してみましたが、最終的には最も精度の良いXGBoostの上位5つを対象とした結果、約56%まで精度を向上させることが出来ました。交互作用特徴量と多項式特徴量が効果的であることが分かります。
日付のダミー変数の付与
前回も作成した日付情報のダミー変数を作成し、精度に影響があるか確認します。前回は月・日・曜日をそれぞれ対象としましたが、「日」の情報に関しては前回重要度を判定した際、高く位置付けられていなかった為、今回は月と曜日のみ対象としています。
#ワンホットエンコーディング
## 曜日(月曜が0, 日曜が6)情報の抽出
dummyData = pd.DataFrame({ 'month' : merge_Data['Date'].dt.month,'weekday' : merge_Data['Date'].dt.dayofweek})
## 月、曜日情報をダミー変数へ変換
dummyData = pd.get_dummies(dummyData, columns=['month','weekday'])
## 最初の5行を表示
dummyData.head()
追加して精度を測りなおしましたが、精度が下がる結果となりました。日付情報のダミー変数に関しては有効ではないようなので、説明変数からは外すことにします。
# 交差検証
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable, answers, cv=5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
Cross-Validation scores: [0.53167702 0.56273292 0.53043478 0.51930262 0.52303861]
Average score: 0.5334371881840613
モデルベース特徴量選択による特徴選択
有用な特徴量の表現の拡張出来た為、次は不要と思われる特徴量を削ることにより精度が向上するかを確認します。今回はモデルベース特徴量選択により特徴量の判定を行い、抽出した特徴量で再度学習させます。
今回はestimatorにランダムフォレスト、LightGBM、XGBoostを使用し、それぞれでの精度を確認しました。いずれの手法でも精度が向上しており、現地点で全ての特徴量が重要ではなく、有用な特徴量に絞り込む必要が出てきたと考えられます。
- ランダムフォレスト
# 交差検証
## 選択された特徴量のみにデータを変換
explanatory_variable_RF = selector_RF.transform(explanatory_variable)
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable_RF, answers, cv=5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
モデルベース特徴量選択(RandomForest):トレーニングデータに対する正解率:59.51492537313433%
モデルベース特徴量選択(RandomForest):テストデータに対する正解率:55.15527950310559%
Cross-Validation scores: [0.59378882 0.57267081 0.58509317 0.53300125 0.55541719]
Average score: 0.567994245183048
- LightGBM
# 交差検証
## 選択された特徴量のみにデータを変換
explanatory_variable_LGBM = selector_LGBM.transform(explanatory_variable)
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable_LGBM, answers, cv=5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
モデルベース特徴量選択(LightGBM):トレーニングデータに対する正解率:60.72761194029851%
モデルベース特徴量選択(LightGBM):テストデータに対する正解率:57.14285714285714%
Cross-Validation scores: [0.57888199 0.55652174 0.58509317 0.54794521 0.56911582]
Average score: 0.5675115831161096
- XGBoost
# 交差検証
## 選択された特徴量のみにデータを変換
explanatory_variable_XGB = selector_XGB.transform(explanatory_variable)
## 5分割し交差検証
scores = cross_val_score(clf, explanatory_variable_XGB, answers, cv=5)
## 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
## スコアの平均値
print('Average score: {}'.format(np.mean(scores)))
モデルベース特徴量選択(XGboost):トレーニングデータに対する正解率:60.66542288557214%
モデルベース特徴量選択(XGboost):テストデータに対する正解率:56.64596273291925%
Cross-Validation scores: [0.56770186 0.57018634 0.58012422 0.55541719 0.57036115]
Average score: 0.5687581507236064
他のアルゴリズムによる評価
ここまで線形サポートベクターマシーンで評価を行ってきましたが、前回同様、他のアルゴリズムによる精度も確認します。今回はロジステジック回帰、ランダムフォレスト、LightGBM、XGBoostの結果を確認しました。ロジステジック回帰、ランダムフォレストに関してはグリッドサーチを実施していますが、LightGBM、XGBoostに関しては特にパラメーターの指定は行わずに実行しています。
- ロジステジック回帰
Cross-Validation scores: [0.57142857 0.57391304 0.59751553 0.54919054 0.58405978] Average score: 0.5752214908379292
- ランダムフォレスト
- LightGBM
Cross-Validation scores: [0.59130435 0.60248447 0.60869565 0.56039851 0.58530511] Average score: 0.5896376167013451
- XGBoost
Cross-Validation scores: [0.61242236 0.62981366 0.58385093 0.57907846 0.59526775] Average score: 0.6000866316530403
LightGBM、XGBoostがグリッドサーチを行っていないにも関わらず高い精度が出ており、Gradient Boostingが強力な手法であるということを実感します。
更にパラメーターチューニングを行うことにより、より高い精度を出せるのではないかと思われます。
まとめ
世界の主要指数を追加したことにより、最終的に約60%まで精度を向上させることが出来ました。説明変数として有用であると思われますが、単純に追加しただけでは劇的に精度を向上させることは出来ないようです。交互作用特徴量と多項式特徴量を追加した結果やモデルベース特徴量選択の結果から、データの表現方法にまだ工夫の余地があるではないかという印象を個人的には持ったため、次回はテクニカル指標を説明変数へ加えて精度が改善されるか確認を行いたいと思います。
記事執筆終了地点のソースコード
参考書籍
オライリーから出版されているの「Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎」の内容を参考にしています。機械学習に必要な基礎知識が網羅的に記載されており、これから機械学習を始めようと思っている方にはとてもおすすめです。